Hire a Deep Learning Engineer to build and optimize neural networks for vision, NLP, and forecasting. Launch production models that reduce costs and drive growth.
Custom
Deep Learning Development
You can hire
Deep Learning Engineer
proficient in delivering high-quality and user-optimized frontend solutions that match all the project's goals and challenges.
Migration to
Deep Learning
Our software engineers will examine the existing software solution and technology stack to advance it with
Deep Learning
and execute the migration to newer frameworks, ensuring high performance and quality.
Product Scaling
To unlock new value from your software, we review its infrastructure, rewrite or rebuild its modules and functionality, ensuring accurate and rapid optimization to preserve your product's power.
Hire
Deep Learning Engineer
For Your Needs
Access technical expertise in a short time
Quickly hire a
Deep Learning Engineer
to fill in a project’s skill gaps and integrate them into the workflow.
Scale up with no time to get your team
Hire
Deep Learning Engineer
to augment your team with extra skills without committing to lengthy staff employment.
Professional team for specific purposes
We can lend you
Deep Learning Engineer,
QA and DevOps engineers, UX/UI designers, and any expertise required.
Hire
Deep Learning Engineer
now for Your Needs!
Hire
Deep Learning Engineer
to get the right specialists that will cater to the needs of your project fast. Apply to us, and we’ll get back to you to define all the requirements to candidates.
Other Hiring Solutions We Provide
Hire
Deep Learning Engineer
For Your Process Needs
Our development team applies thoroughly-tested
Deep Learning
practices to implement mobile and web solutions to maximize the value of the product.
Quick call
We’ll schedule a call and understand your requirements and devs you need to hire.
First candidates
Get selected candidates who have been thoroughly evaluated in just a few days.
Select
Get a list of devs who match the best. You select the developers you like.
Interview
We contact selected devs in 48 hours. You interview & choose the best one.
Case Studies We Delivered
Our development team applies thoroughly-tested .NET practices to implement mobile and web solutions to maximize the value of the product.
Our Expertise in Case Studies
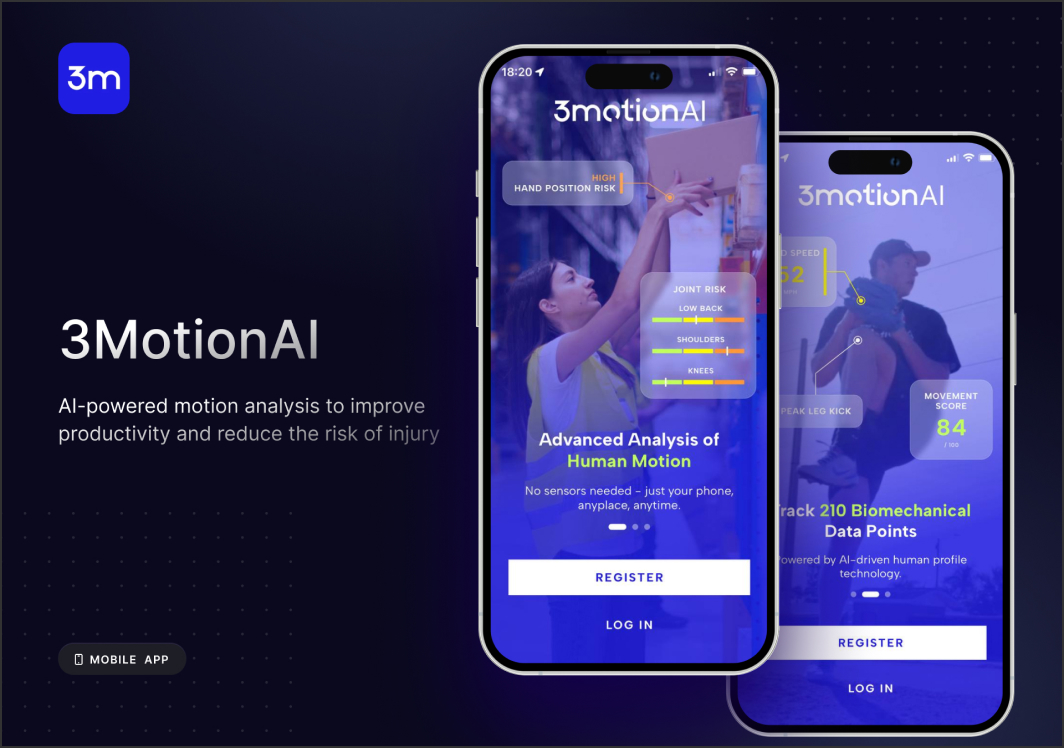
Transforming Motion Analysis with Cutting-Edge AI-Powered iOS Technology
An advanced platform leveraging AI-driven motion analysis to enhance performance, improve safety, and provide actionable insights across healthcare, sports, and fitness industries.
Our Expertise in Case Studies
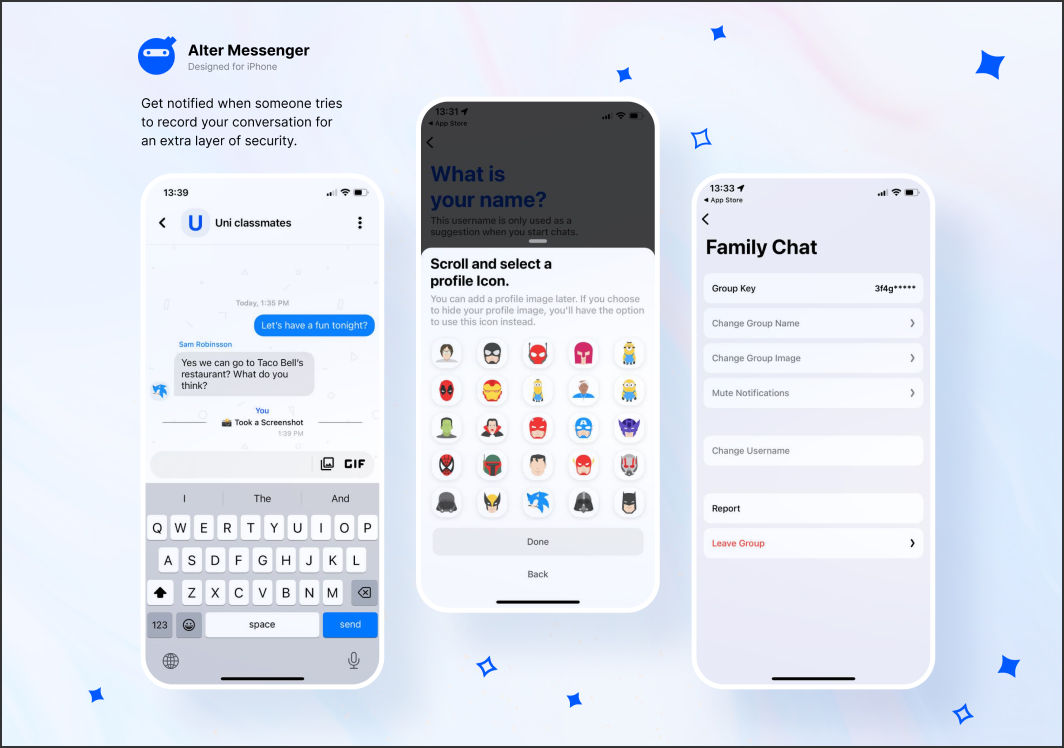
Secure Communication Platform
This project was an exciting opportunity to develop Custom Messenger, a secure communication platform focused on privacy and efficiency. Smooth communication and seamless collaboration with the client made the development process highly productive and enjoyable.
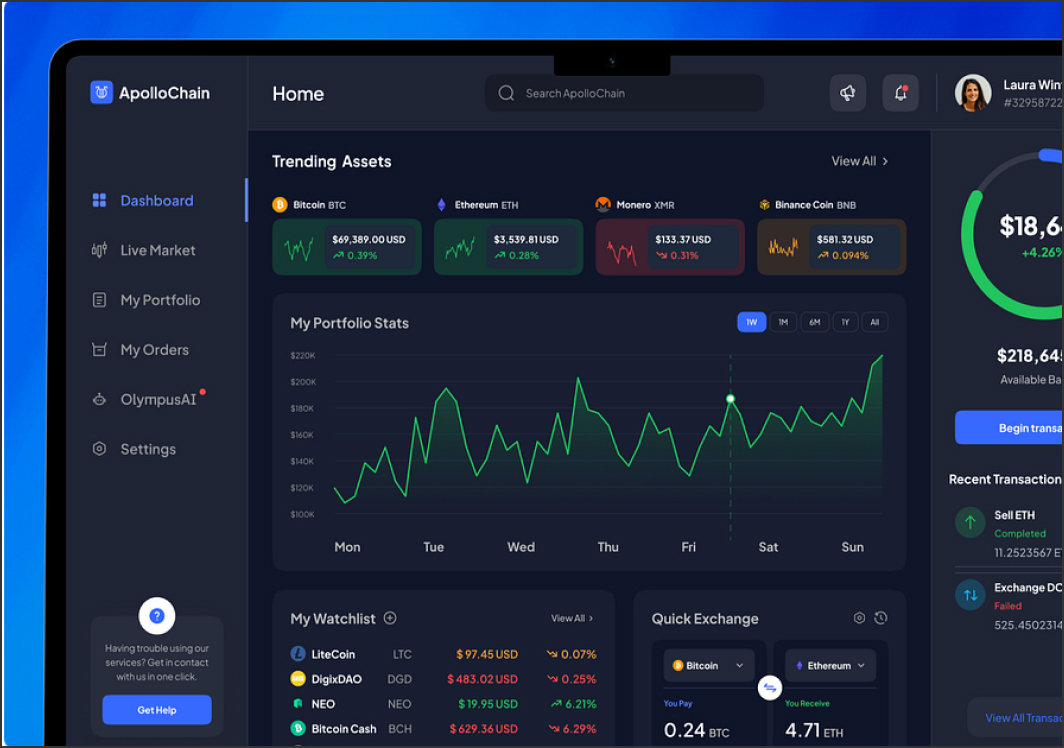
Our Expertise in Case Studies
Developing was an exciting challenge, focused on creating a secure and efficient blockchain-based trading platform. Collaboration with the client was seamless, ensuring a smooth and productive development process.
Our Expertise in Case Studies
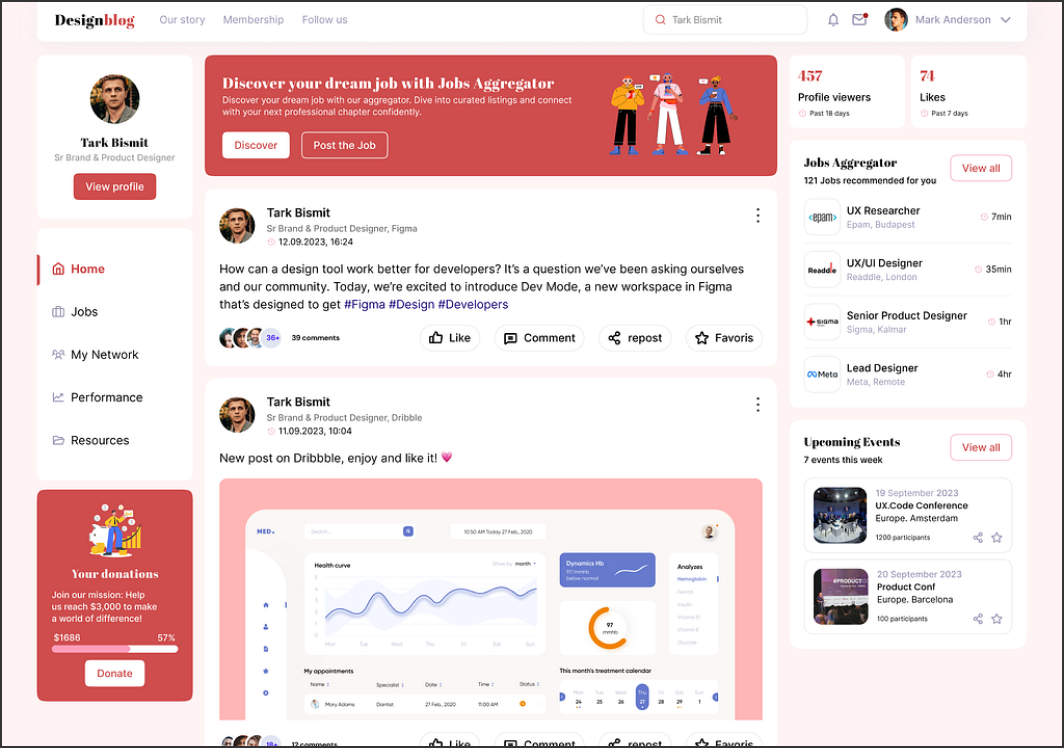
Insights for Designers and Innovators
Creating this blog was a rewarding journey, combining creativity and functionality. Seamless collaboration with the client ensured a user-friendly and inspiring platform.
Our Expertise in Case Studies
Innovative Health & Fitness App
This project was an inspiring journey for us, marked by smooth communication and seamless collaboration with the client. The development process was both efficient and rewarding.
Our Expertise in Case Studies
Advanced Analytics Platform
This project was an exciting challenge for us, with smooth and effective communication throughout. Collaborating with the client was seamless, making the development process both productive and enjoyable.
Our Expertise in Case Studies
AI-Based App for Seamless Video and Lecture Transcriptions
We’re very happy with Cleveroad. They seem to work in the way that we do, and we have a close collaboration with them. Every day we talk to the developers and outline what needs to be done.
Our Clients
How to Hire a Deep Learning Engineer: A Practical Guide for Founders and Business Owners
Hiring a Deep Learning Engineer can turn scattered experiments into production-grade AI that drives measurable value. The right person bridges research and engineering: they design datasets, train models, ship services, and monitor outcomes against business KPIs. This guide shows what to look for, how to structure an efficient hiring process, and where deep learning adds the most impact across product, operations, and growth.
Why Hire a Deep Learning Engineer
Business value
Automation & accuracy: Replace manual decisions with models that scale consistently.
Product differentiation: Personalisation, recommendations, and intelligent assistance baked into the core experience.
Efficiency: Faster workflows via computer vision, speech/NLP, and multimodal models that remove repetitive work.
Common impact areas
Smart search and recommendations, churn prediction, fraud/risk signals.
Document understanding (OCR, entity extraction), content moderation and summarisation.
Vision pipelines for QA, defect detection, and logistics optimisation.
Core Skills to Look For
Technical stack
Frameworks: PyTorch/TensorFlow, transformers, diffusion, RLHF/PEFT for LLMs.
Serving: FastAPI, Triton, TorchServe; vector DBs for retrieval-augmented workflows.
Optimisation: FP8/INT8 quantisation, distillation, pruning; A/B tests for model changes.
Process tips
Start with clearly scoped pilots; track a single KPI.
Maintain an evaluation suite and golden datasets.
Separate dev/test/prod with promotion and rollback controls.
30–60–90 Day Onboarding Plan
30 days: Audit data, ship a baseline model + eval harness, define latency/quality targets.
60 days: Deploy to a small traffic slice with monitoring and guardrails; collect feedback.
90 days: Optimise cost/latency, expand coverage, document runbooks, and hand over ownership to relevant teams.
Page Updated: 2025-10-06
Trusted by Businesses Worldwide
See what our clients say about working with Alpina Tech
HTMLCSSHugo+5
Alpina tech did a good job during the discovery phase of our project
4.9 / 5
StrapiNext.jsReact+9
I had the opportunity to work with Alpina Tech and the experience was very positive. He successfully achieved the goals set, demonstrating talent and commitment at every stage of the work. Moreover, he was always attentive to my instructions and consistently available, which greatly facilitated communication and the development of the project. I highly recommend his work without hesitation.
5.0 / 5
Next.jsReactJavaScript+5
Alpina Tech is not only a very talented dev, but he's a fantastic partner who has a rich business acumen and is quick to complete anything you throw at him. He knocked out work in a single day that I wasn't expecting for a week. Will definitely work with him again.
5.0 / 5
React NativeReactNode.js+7
Alpina Tech always responded promptly and got a lot done in the limited environment we had. If things weren’t clear, he’d message and make sure he has the scope right. I highly recommend him for full stack development.
5.0 / 5
UX/UI DesignFigmaLanding Pages+4
I had the opportunity to work with Alpina Tech on the design of several landing pages and a UI kit, and I couldn’t be happier with the results. He managed to deliver high-quality designs in a very short time. The landing pages were beautifully crafted, and the UI kit was exactly what we needed to streamline the project. On top of that, he generously created ad banners at no extra cost, which was a great bonus. Throughout the entire process, communication was smooth, and he was always quick to make adjustments based on my feedback. I’m thrilled with the final outcome and would definitely love to work with him again. Highly recommend!
5.0 / 5
React.jsReactNext.js+12
Working with Alpina Tech on a headless CMS project built with Strapi, Node.js, and Next.js was a great experience. His deep understanding of modern frontend frameworks, API development, and server-side rendering (SSR) ensured a smooth and efficient development process. Alpina Tech showcased excellent React.js and Next.js skills, implementing dynamic UI components with optimal performance and seamless API integrations. His expertise in RESTful and GraphQL APIs, combined with a solid grasp of backend development in Node.js, made the project highly scalable and maintainable. Additionally, his proficiency in frontend optimization, component-based architecture, and responsive design ensured that the final product was both fast and user-friendly. I highly recommend Alpina Tech to anyone looking for a skilled full-stack developer who excels in headless CMS solutions, Next.js development, and API-driven web applications.
5.0 / 5
SwiftSwiftUIUIKit+8
We worked with Alpina Tech, a top-tier Apple ecosystem developer specializing in Swift, SwiftUI, UIKit, and Combine. Delivered a seamless, high-performance app with Core Data, iCloud Sync, AVKit, MapKit, and Push Notifications. Optimized for iOS, watchOS, and macOS, ensuring smooth performance and App Store compliance. We were very happy with the outcome of the app we commissioned to develop and look forward to working again with this developer.
5.0 / 5
JAMstackHugoNext.js+10
I hired Alpina Tech to build a custom Hugo website. He was a pleasure to work with. He took the time to understand exactly what I wanted at the beginning of the project, and he then proposed a much better way of achieving that. He communicated regularly, provided clear and timely updates, offered ongoing support with my website, and took a 'customer first' approach. Overall, I'm really happy with the website and I would definitely work with Alpina Tech again if I need more web development in the future.
5.0 / 5
Next.jsReactSanity+7
Alpina Tech was incredibly helpful and a pleasure to work with! He not only assisted with improving the SEO of my startup but also fixed a challenging Sanity bug with great patience and professionalism. His expertise and attention to detail were invaluable, and he did an excellent job overall. Highly recommended!
4.9 / 5
UI/UX DesignFigmaWeb Design+3
I had the pleasure of working with Alpina Tech on the UI/UX design for my public website, and I am extremely impressed with his work. He significantly expanded and improved upon the original design I already had, seamlessly integrating enhancements that perfectly matched the existing style. His ability to develop great-looking features while staying true to the original concept was remarkable. Communication with Alpina Tech was excellent throughout the project. He was responsive and accommodating, making several tweaks based on my requests to ensure everything was just right. I am thoroughly satisfied with the outcome and wouldn't hesitate to collaborate with him on future projects. Highly recommend!
5.0 / 5
JekyllJAMstackHTML+5
Working with Alpina Tech was a great experience. He is knowledgeable and delivers high-quality work. The agency boasts a wide range of talent, making it a good choice for various projects. Communication was consistently excellent, and Alpina Tech ensured that every aspect of the project worked as expected. The work was completed on time, which was greatly appreciated. I highly recommend both Alpina Tech and the agency for future collaborations.
5.0 / 5
UI/UX DesignFigmaLanding Pages+4
Alpina Tech and the team have completed the design quickly and it looks great. They are very responsive and were able to quickly make adjustments that I have requested.
5.0 / 5
iOSSwiftSwiftUI+3
Alpina Tech is awesome, he fixed a complicated bug on VPN iOS app in two hours.
5.0 / 5
React NativeReactiOS+5
Tyler V.
5.0 / 5
HugoJAMstackHTML+3
Alpina Tech did an excellent job guiding us through the process and helping us achieve our project goals.
5.0 / 5
GitHub PagesHTMLCSS+4
Alpina Tech helped us launch a research project website. Thank you for being available on short notice!
5.0 / 5
Technical SEOWeb StrategyManagement
I had the pleasure of working with Alpina Tech on leadership and technical projects. The team is highly motivated, strategically minded, and has exceptional technical SEO expertise. Their approach significantly boosted our digital presence. I highly recommend Alpina Tech for engineering and leadership-driven projects – a truly valuable partner.
5.0 / 5
HTMLCSSJavaScript+4
Alpina Tech demonstrates all the right qualities of a strong development team – deep frontend expertise, great communication, and a proactive work attitude. A reliable partner for any technical project.
5.0 / 5
Web DevelopmentFrontendHTML+3
Alpina Tech is a very professional and reliable team. Working together on web projects was extremely successful. The team showed strong technical knowledge and excellent organizational skills.
5.0 / 5
Let’s just { Make it together! }
Learn how our services can improve your business processes, customer experience, and drive growth.
Discovery Session
Get a lightning-fast, SEO-optimized, high-performance web app for:
• SaaS platforms
• Marketplaces
• Marketing websites
• News portals
• Catalogs & listings
Meeting agenda
Define goals & product scope
Quick technical SEO check-up
Outline your development roadmap
30 min
Web conferencing details provided upon confirmation.
Meet our team
Success!
Form was sent to our team. We will contact you soon.
Get Your Estimate
Tell us about your project and we'll get back to you with an estimate.
Discovery Session
Get a lightning-fast, SEO-optimized, high-performance web app for:
• SaaS platforms
• Marketplaces
• Marketing websites
• News portals
• Catalogs & listings
Meeting agenda
Define goals & product scope
Quick technical SEO check-up
Outline your development roadmap
30 min
Web conferencing details provided upon confirmation.