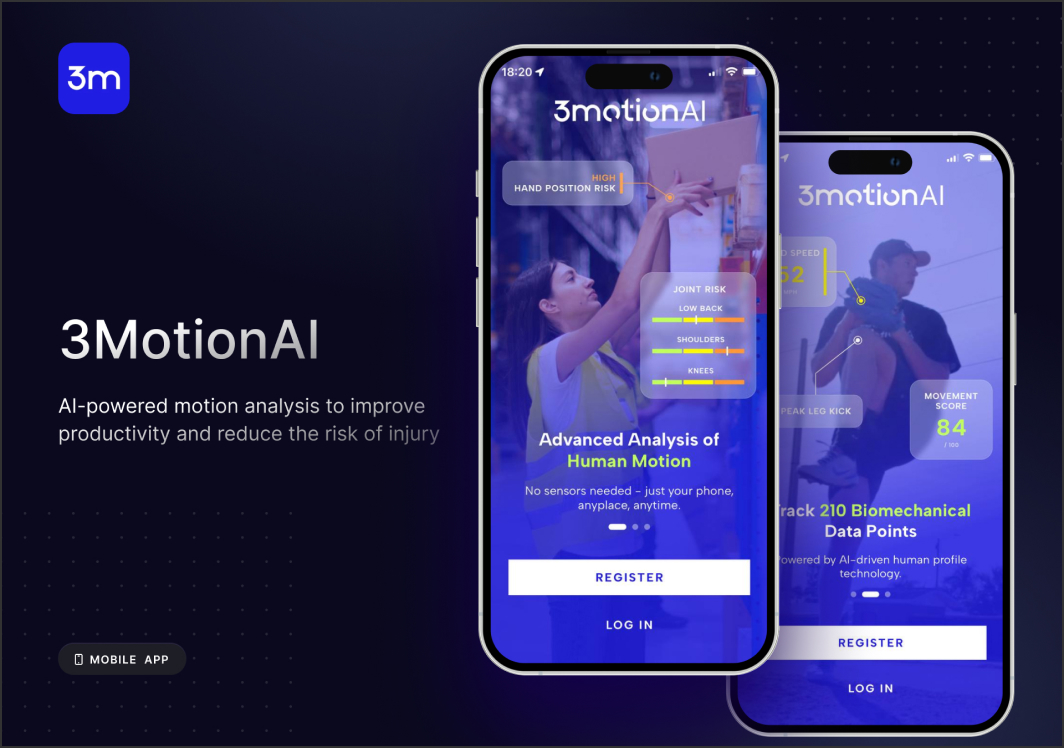
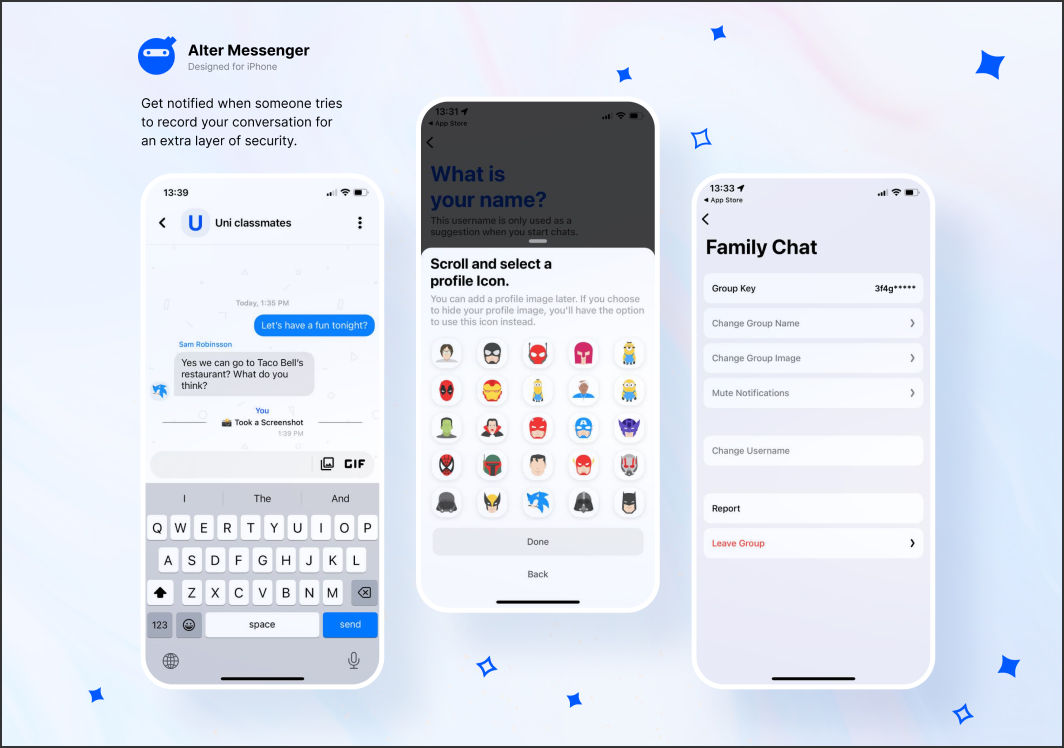
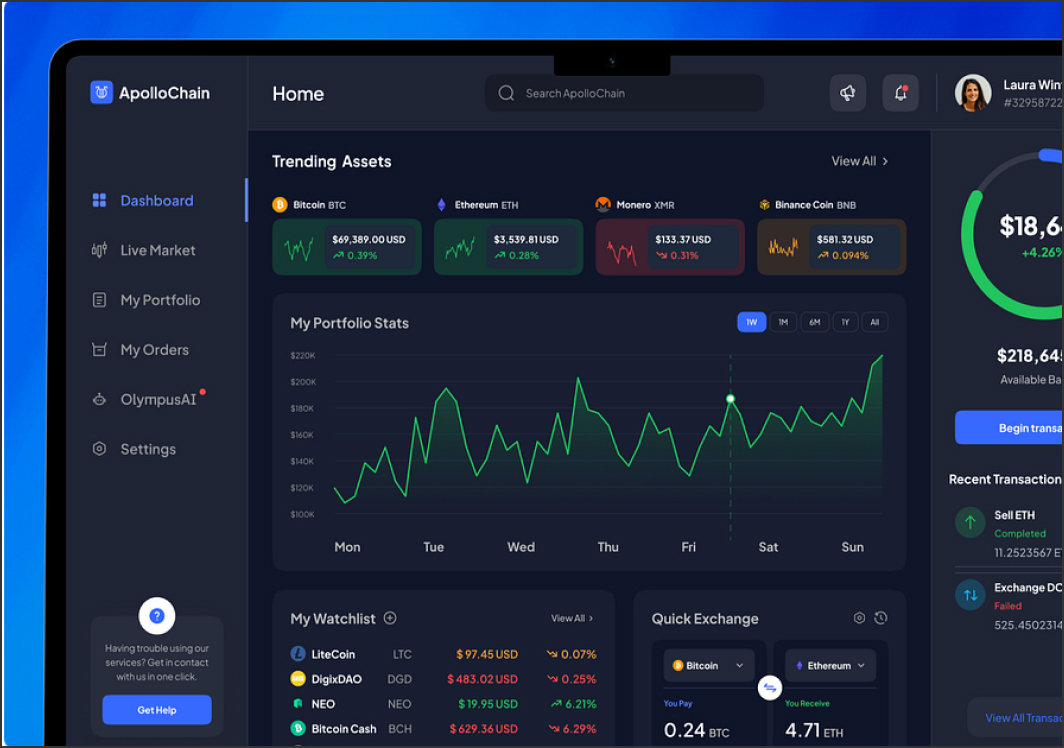
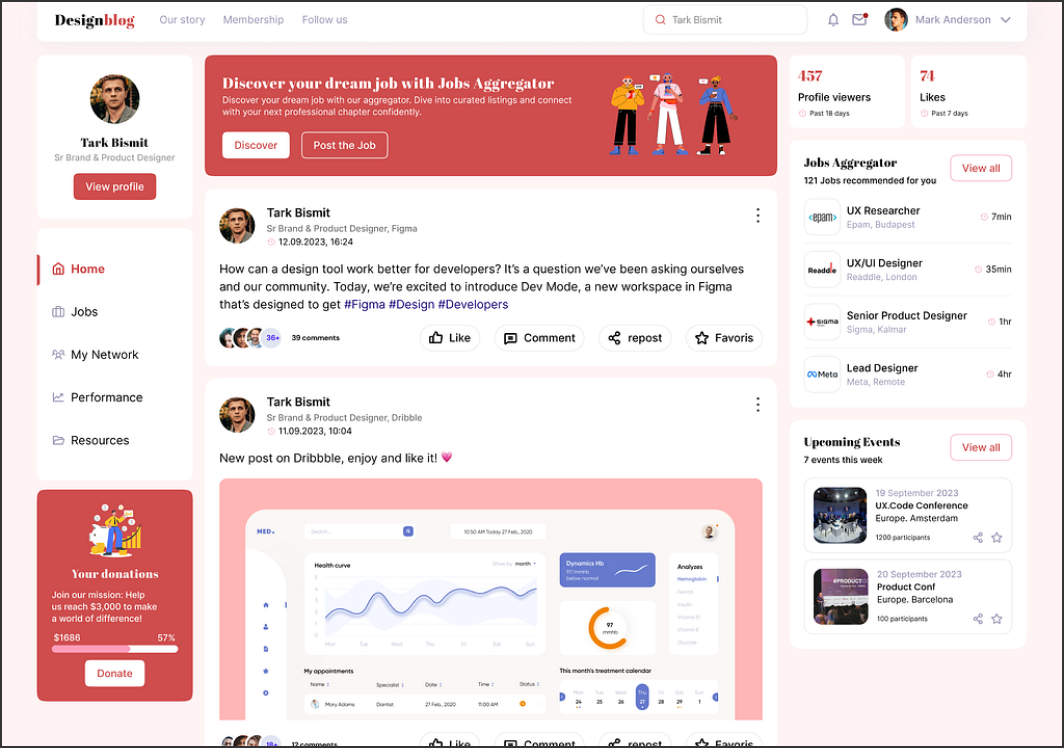
Hiring a Daptin developer means working with a platform that auto-generates REST and GraphQL APIs from database schemas. Daptin eliminates boilerplate CRUD logic, but the architecture of the underlying data model determines whether the system remains scalable or turns into an unmanageable tangle of auto-generated endpoints.
Without deliberate schema design, teams end up with redundant tables, unclear entity relationships, and API surfaces that expose more than they should. Access control rules, data validation, and workflow automation all depend on how the initial data structure is configured.
We approach Daptin projects by designing the relational schema first — defining entities, relationships, and permission boundaries before the platform generates any API surface.
Data Modeling and API Structure
Daptin derives its entire API layer from the database schema. Every table becomes a resource with full CRUD operations, sub-resources for relations, and automatic pagination. This is powerful but requires careful planning to avoid exposing unnecessary endpoints or creating inconsistent data access patterns.
We structure Daptin implementations with:
- normalized schemas that prevent data duplication across resources
- explicit relationship definitions that map to predictable API sub-routes
- column-level permission configurations to enforce data access boundaries
- validation rules embedded at the schema level rather than in client logic
This ensures the auto-generated API is clean, predictable, and ready for frontend consumption without additional middleware.
Authentication, Workflows, and Integration Layer
Daptin includes built-in OAuth2 authentication, user management, and action workflows. These features accelerate development but require precise configuration — misconfigured permissions or poorly designed workflows create security gaps and operational bottlenecks.
We configure Daptin environments by:
- implementing role-based access control with granular resource-level permissions
- designing stateful workflows for content approval, publishing, and data transformations
- integrating external services through Daptin’s action system and webhook triggers
- optimizing database queries to prevent performance degradation as data volume grows
The goal is a backend that handles authentication, authorization, and content operations without custom API code.
Daptin as a Scalable Content Backend
Daptin is not a traditional CMS — it is a data-driven backend framework that generates content APIs from structured schemas. Teams that treat it as a plug-and-play solution without investing in schema architecture quickly hit scalability and maintainability walls.
We treat Daptin development as database architecture combined with API design — ensuring the auto-generated layer serves your product requirements without requiring constant manual intervention as the data model evolves.
Page Updated: 2026-03-19